Agentic Data Stack Evaluation Framework: 6 Principles That Define Agent-Ready Systems
Evaluate agent-ready data platforms with 6 principles: CLI/MCP interfaces, progressive skills, versioning & rollback, serverless scalability, dual-mode execution, and stability-first design.
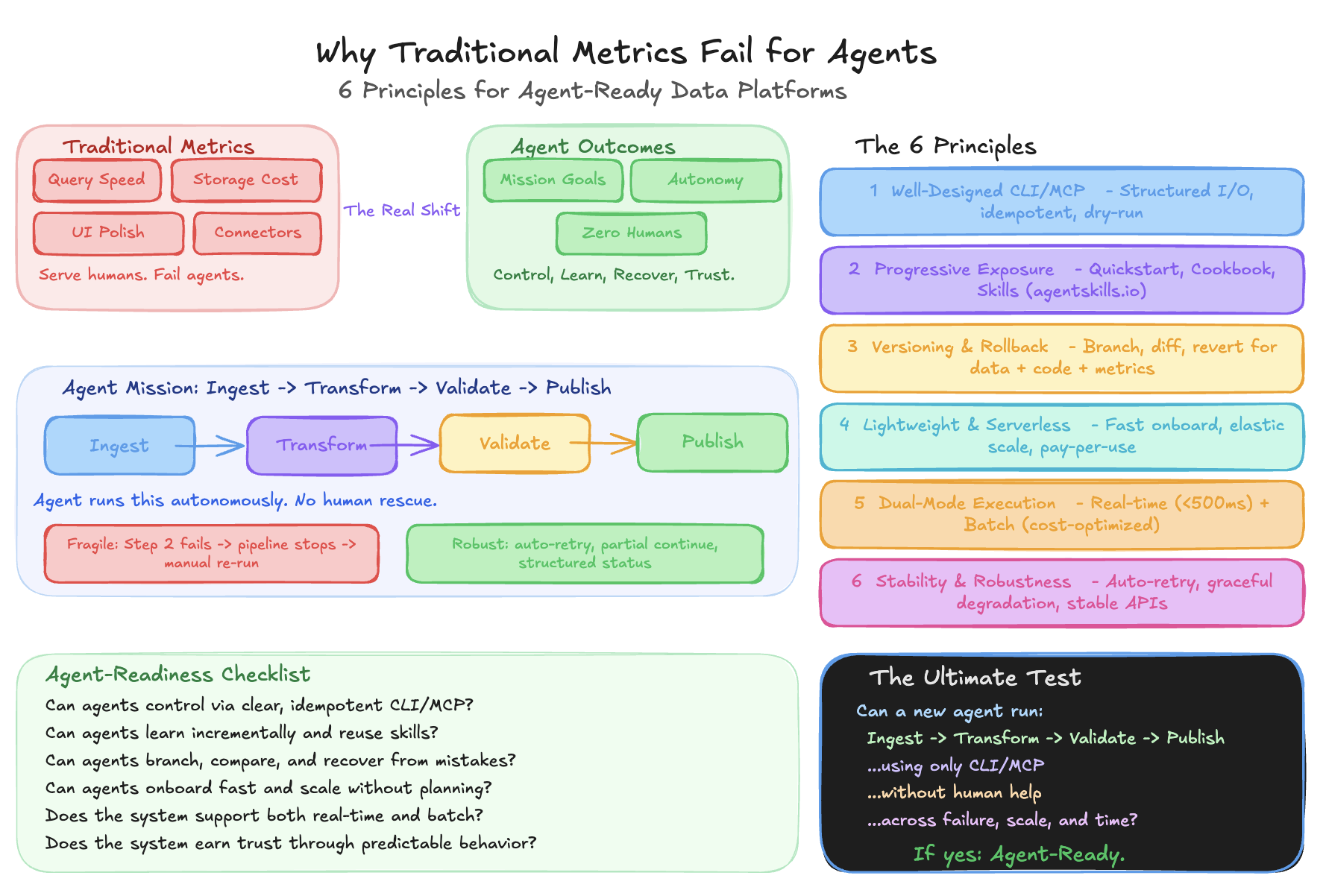
Why Traditional Metrics Fail for Agents
Traditional data platforms optimize for query speed, storage cost, connector count, UI polish. These serve human users. They tell you nothing about agent-readiness.
Agents don't use dashboards. They parse structured data. They don't read tutorials. They need machine-readable contracts. They don't call support. They need structured error codes.
A warehouse scoring 95/100 on traditional metrics can be nearly unusable for agents — unstructured errors, no idempotency, no versioned metrics, constant human rescue for routine failures.
The real shift: from adoption primitives (Can agents technically access it?) to mission outcomes (Can agents turn goals into production artifacts?). CLI access is table stakes. The question is: can agents accomplish sustained, autonomous execution?
Six principles separate agent-ready platforms from chatbot wrappers.
Principle 1: Well-Designed CLI/MCP
CLI and MCP servers are the primary interfaces agents use. They must be first-class contracts, not afterthoughts.
What good agent interfaces look like:
- Minimal parameters — no guessing which of 50 flags to use
- Structured I/O — JSON/YAML, not prose or HTML error pages
- Actionable error codes — not "Pipeline failed. Contact support."
- Idempotent operations — same command twice, same outcome
- Dry-run modes — preview before execution
- Complete coverage — every UI operation available via CLI/MCP
Bad: Different auth patterns per tool. HTML error pages. Agents parsing log files to understand state.
Good: Single auth across all endpoints. Structured JSON errors with suggested fixes. --dry-run on every destructive operation. Machine-parseable state queries.
An MCP server exposing a component's full functionality — typed parameters, structured responses, clear errors — dramatically cuts integration cost for any agent framework.
Test: Can a new agent run data ingestion → transformation → validation → publish using only CLI/MCP, without human help?
Principle 2: Progressive Exposure — Skills & Docs
Skills and documentation let best-practice experience be reused by agents. The key is progressive exposure — layered knowledge consumed as needed.
500 pages of API docs dumped on an agent doesn't work. Zero docs doesn't work either. Layer it:
- Quickstart: 10-line script to first success
- Cookbook: "Load from S3", "Handle schema drift", "Retry on timeout"
- Reference: Full API specs, error codes, limits
- Troubleshooting: "Error 429" → "Rate limit" → "Exponential backoff (code)"
Beyond docs, skills turn repeated work into reusable capabilities. A prompt is ephemeral. A skill is durable — tested instructions with clear boundaries and failure modes, following the agentskills.io open standard.
Instead of every agent re-prompting "check for nulls, duplicates, schema drift":
data-quality-check --table orders --checks null,duplicate,schema --threshold 95Consistent invocation. Comparable scores. Chainable into pipelines. No reinvention.
Test: >80% first-attempt success for documented tasks. Recurring tasks codified into reusable skills.
Principle 3: Versioning & Rollback
Next-token prediction cannot guarantee zero errors. LLMs are probabilistic — they will make mistakes. The question isn't whether, but whether you can recover safely.
Everything must be versioned:
- Data: Iceberg checkpoints, time travel, table snapshots
- Code: Pipeline logic in git
- Metrics: Definition changes tracked over time
- Environments: Dependency versions, config snapshots
- ETL Jobs: Re-entrant guarantees — rerun produces correct results, not duplicates
data-stack branch create "add_customer_ltv_metric"
data-stack run pipeline --dry-run
data-stack validate --compare-to main
data-stack commit "Added LTV metric with 30-day window"
data-stack diff main..add_customer_ltv_metric
data-stack merge add_customer_ltv_metric --into main
data-stack revert --to-commit abc123 # when things go wrongWithout versioning, an agent updates "revenue" from SUM(order_total) to SUM(order_total) - SUM(refunds). Historical reports silently change. No record. Breaking change goes unnoticed for weeks.
With versioning, agents compare across versions, understand why numbers changed, rollback bad definitions, validate before promoting.
Test: % of critical components (data, code, metrics) under version control with complete lineage.
Principle 4: Lightweight Client & Serverless Scalability
A lightweight client is the key to onboarding. Elastic scalability handles what comes after.
If an agent needs a 2GB runtime, 15 environment variables, and dedicated compute before its first query — most workflows never start. Agent-ready systems offer a thin client, minimal dependencies, first success in minutes.
But one agent running one pipeline is easy. Hundreds of agents running concurrent workflows need infrastructure that scales without manual capacity planning: auto-scaling compute, pay-per-use pricing, parallel execution without contention.
Heavy client: Spin up a Spark cluster (5 min cold start, $2/hr minimum) for a simple aggregation.
Lightweight + serverless: Thin client, serverless endpoint, 2-second first query, auto-scales to 1000 concurrent queries at $0.001 each.
Test: Time from zero to first operation. Cost at 10x and 100x concurrency.
Principle 5: Low Latency & Cost-Effective Modes
Agents serve different scenarios. Customer-facing work demands low latency. Batch jobs demand cost efficiency. Just like LLMs have fast mode and thinking mode.
- Interactive: User asks a question, agent queries and returns an answer. Sub-second expected.
- Batch: Agent rebuilds a pipeline or backfills data. Minutes to hours acceptable. Cost is king.
| Dimension | Low-Latency | Cost-Effective |
|---|---|---|
| Use case | Real-time queries, dashboards | Batch ETL, backfills, training |
| Latency | <500ms | Minutes to hours |
| Compute | Hot caches, reserved | Spot instances, queued |
| Cost | Higher per-query | Lowest per-record |
A query engine that only does real-time (expensive) or only does batch (slow) fails half the use cases. Offer both. Switch via a single parameter.
Test: P95 latency for interactive queries. Cost-per-record for batch. Mode switching without code changes.
Principle 6: Stability & Robustness
In the AI era, code creation cost approaches zero. Trust becomes the highest value. Stability outranks performance. A robust system with a stable interface determines software's lifecycle.
A blazing-fast system that breaks unpredictably is worse than a slower one that never surprises you.
Stability for agents means: predictable behavior, backward-compatible interfaces, graceful degradation under load, transparent failure modes.
Agent-ready systems absorb infrastructure noise silently: auto-retry on timeouts, auto-throttle on rate limits, failover on transient outages, isolate partial failures. Agents spend energy on the mission, not babysitting the platform.
Fragile: Step 2 fails from temporary overload → entire pipeline stops → manual re-run.
Robust: Step 2 fails → auto-retries with backoff → independent steps proceed → structured status: "80% complete, Step 2 retrying" → auto-completes when recovered.
Interface stability anchors the lifecycle. If every minor version changes CLI flags or MCP schemas, every agent workflow breaks. Treat agent interfaces with the same rigor as public APIs — versioned, documented, clear deprecation paths.
Test: Mission completion rate despite failures. Auto-recovery rate. Breaking interface changes per year (target: 0).
The 6-Principle Checklist
| # | Principle | Core Question |
|---|---|---|
| 1 | Well-Designed CLI/MCP | Can agents control through clear, complete, idempotent interfaces? |
| 2 | Progressive Exposure | Can agents learn incrementally and reuse best practices? |
| 3 | Versioning & Rollback | Can agents branch, compare, and recover from mistakes? |
| 4 | Lightweight & Serverless | Can agents onboard fast and scale without planning? |
| 5 | Dual-Mode Execution | Does the system support both real-time and batch? |
| 6 | Stability & Robustness | Does the system earn trust through predictable behavior? |
Agent-readiness isn't about features or UI polish. It's whether agents can control, learn, recover, scale, optimize, and trust the system — turning intent into production artifacts, autonomously.
Read more: Agentic Data Stack Evaluation FAQ — practical Q&A for platform teams evaluating agent-readiness.
Explore the stack: Browse 27+ open-source components in our Resource Hub — with MCP support, CLI interfaces, and agent skills tracked for each.