Agentic Data Stack Evaluation FAQ: Practical Answers for Platform Teams
Common questions about evaluating agent-ready data stacks — from measuring readiness quantitatively to making existing tools agent-friendly.
FAQ: Evaluating Agent-Ready Data Stacks
Q: What's the difference between the Modern Data Stack and the Agentic Data Stack?
A: The Modern Data Stack (MDS) — a term popularized by a16z's influential 2020 report — describes the wave of modular, cloud-native, SQL-centric tools designed to empower human analysts and data engineers: cloud warehouses, ELT pipelines, BI dashboards, and reverse ETL.
The Agentic Data Stack builds on top of MDS but shifts the primary operator from humans to AI agents. As discussed in the a16z podcast AI, Data Engineering, and the Modern Data Stack, the industry is evolving from tools designed for human point-and-click workflows to platforms where agents autonomously orchestrate data pipelines.
Architecture Comparison
Modern Data Stack (2020) — The a16z reference architecture for cloud-native data infrastructure:
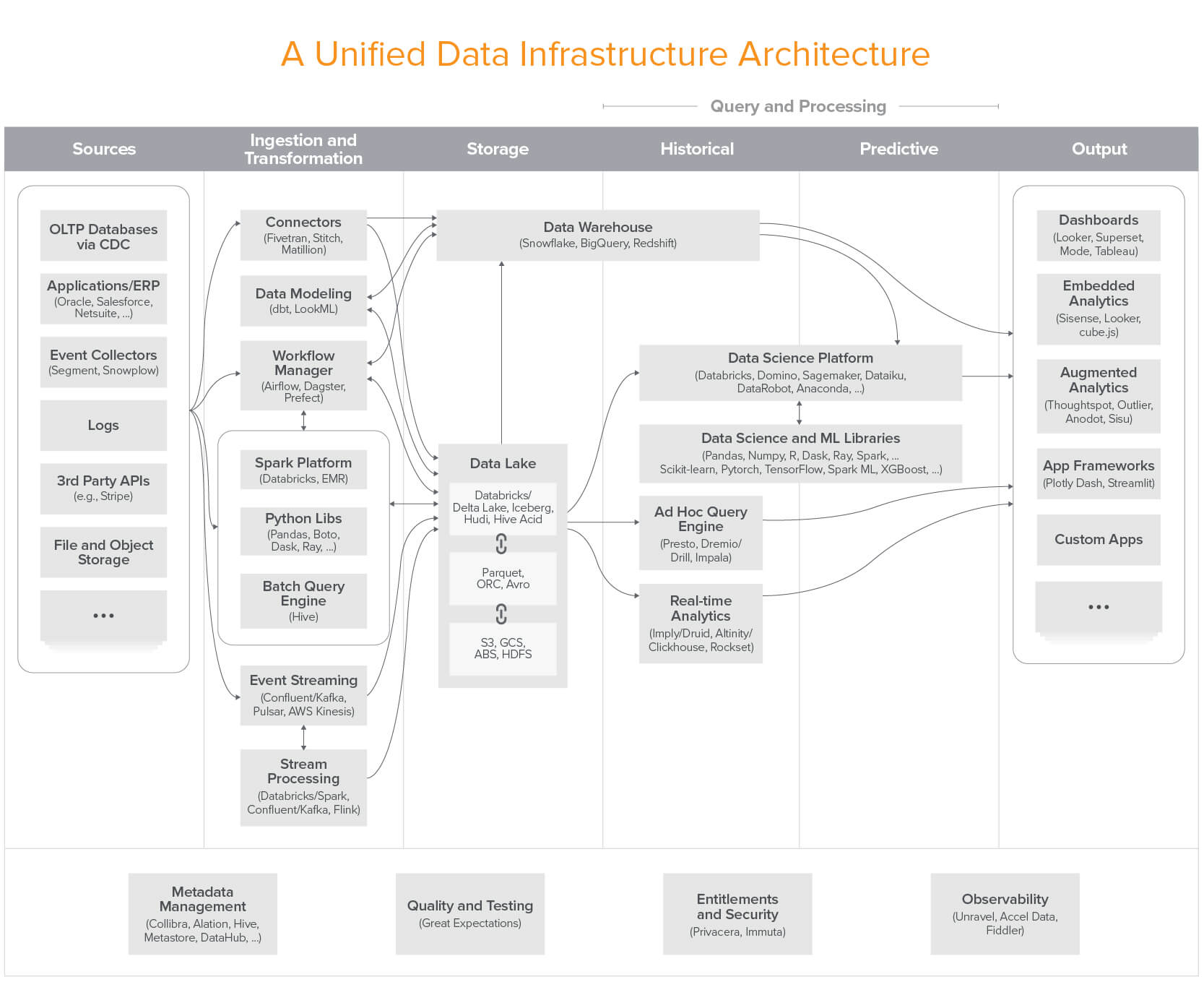 Source: a16z — Emerging Architectures for Modern Data Infrastructure
Source: a16z — Emerging Architectures for Modern Data Infrastructure
Agentic Data Stack (2026) — The MDS becomes the foundation layer; Data Agents and Agent Infra are the new additions:
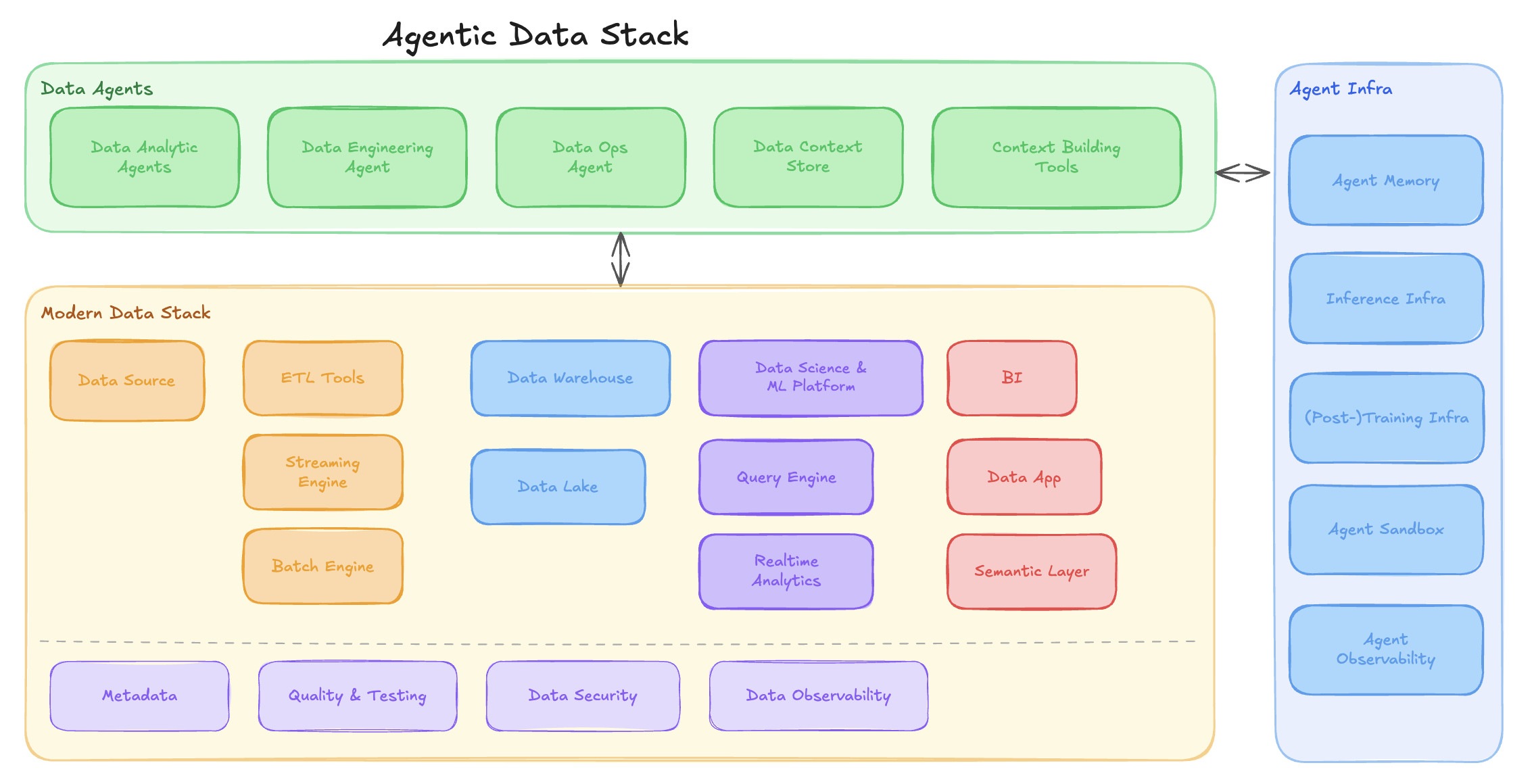 The Agentic Data Stack wraps the Modern Data Stack with an agent layer (Data Agents) and supporting infrastructure (Agent Memory, Sandbox, Observability).
The Agentic Data Stack wraps the Modern Data Stack with an agent layer (Data Agents) and supporting infrastructure (Agent Memory, Sandbox, Observability).
Key Differences
| Modern Data Stack | Agentic Data Stack | |
|---|---|---|
| Primary operator | Human analysts & engineers | AI agents with human oversight |
| Interface | Dashboards, SQL editors, drag-and-drop | CLI, MCP servers, structured APIs |
| Error handling | Toast notifications, logs for humans | Structured error codes + suggested recovery |
| Iteration | Manual edit → run → check | Autonomous retry with versioned state |
| Knowledge | Docs, wikis, tribal knowledge | Agent skills, machine-readable specs |
| Orchestration | Scheduled DAGs | Goal-driven missions with adaptive pipelines |
The MDS gave us the building blocks. The Agentic Data Stack makes those blocks operable by machines. For a deeper introduction, see What Is the Agentic Data Stack?.
Q: Is having a CLI/API enough to be agent-ready?
A: No. A CLI is an "adoption primitive," not proof of agent-readiness. The real test is whether agents can control, learn, debug, recover, version, and improve using that CLI. Many SQL engines and ETL tools have APIs but return unstructured errors, lack idempotency, or don't support dry-run modes—making them difficult for agents despite having programmatic access.
Q: How do I measure agent-readiness quantitatively?
A: Track these metrics over 20 missions:
- Mission completion rate (target: >85%)
- Human interventions per mission (target: <2)
- Auto-recovery rate for failures (target: >70%)
- Cost-per-mission trend (target: -50% from mission 1 to mission 20)
- Time to first success for new agents (target: <1 day)
- Skill reuse rate (target: >60% of missions use existing skills)
Q: Our system is reliable for humans but agents struggle. Why?
A: Human users navigate ambiguity through intuition, asking colleagues, and visual interfaces. Agents need structured contracts — the kind exposed by well-designed catalog services and semantic layers:
- Humans tolerate vague error messages; agents need error codes + suggested fixes
- Humans can read prose documentation; agents need structured API specs (like Iceberg REST catalog endpoints)
- Humans improvise workarounds; agents need documented recovery paths
A system can be "reliable" (high uptime) but "not agent-ready" (poor observability, inconsistent interfaces, manual recovery steps).
Q: Should we build agent-specific tools or make existing tools agent-friendly?
A: Make existing tools agent-friendly first. Most systems already have the core capabilities agents need—they just expose them poorly. Focus on:
- Adding structured error responses
- Implementing dry-run / explain modes
- Versioning critical state (data, metrics, configs)
- Documenting recovery paths for common failures
- Creating machine-readable observability (logs, lineage) — semantic layers and BI tools are good starting points
Only build agent-specific tools when existing ones have fundamental architectural gaps (e.g., no versioning support at all).
Q: How many skills should an agent-ready system have?
A: Quality over quantity. See real-world examples on our Data Agents resource page. A well-designed system has:
- 3-10 core skills covering 80% of common tasks
- Clear skill boundaries (when to use each)
- Composable primitives (skills combine cleanly)
- Low discovery cost (agents find the right skill quickly)
500 skills = context overload. 5 sharp, tested skills = high leverage.
Q: What's the difference between "versioning" and "backups"?
A: Backups = disaster recovery. Versioning = safe iteration.
- Backups: "Restore everything from yesterday"
- Versioning: "Compare metrics v1 vs. v2, rollback only the metric definition, keep new pipeline code"
Agent-ready systems need granular versioning of data, code, metrics, environments, and skills—not just full-system snapshots. Lake formats like Apache Iceberg provide branching and tagging at the table level, which is exactly the kind of primitive agents need.
Q: Can small teams build agent-ready systems, or is this only for large companies?
A: Small teams can absolutely build agent-ready systems—often more easily than large companies.
Start with:
- Git-based versioning (free)
- Structured logging (open-source tools)
- CLI-first interfaces (less engineering than UIs)
- Lightweight skill documentation (Markdown files)
- Public execution trails (simple JSON logs)
Large companies often struggle because they have legacy systems, organizational silos, and complex approval processes. Small teams can design for agent-readiness from day one.
Conclusion: From Chatbot Wrappers to Agent Operating Environments
The shift from chatbot wrappers to true agent-ready systems requires fundamentally rethinking how data platforms work.
Chatbot wrappers:
- Add conversational interfaces to existing tools
- Generate answers, not artifacts
- Require constant human oversight
- Treat agents as users, not operators
Agent operating environments:
- Provide unified control surfaces
- Generate production-grade, versioned artifacts
- Enable autonomous execution with human direction
- Treat agents as first-class operators
Key Takeaways
- Agent-readiness is not about features — it's about whether agents can control, learn, recover, and improve
- CLI/MCP are table stakes — mission outcomes (intent to artifacts) are the real test
- Skills compound value — reusable, tested capabilities get cheaper over time
- Everything must be versioned — data, code, metrics, environments, skills
- Stability outranks performance — trust is the highest value in the AI era
- Humans provide direction, not constant rescue — aim for <2 interventions per mission
Next Steps
To evaluate your current stack:
- Run the 5-mission test: Have an agent complete 5 representative workflows
- Measure human interventions, completion rate, and debugging time
- Check versioning coverage for data, code, metrics
- Assess skill reuse rate and cost trends
To improve agent-readiness:
- Add structured errors with codes + suggested fixes
- Implement dry-run modes for risky operations
- Version critical state (start with metrics and data)
- Document recovery paths for top 10 failure modes
- Codify recurring tasks into reusable skills
The future of data platforms isn't more features or prettier UIs. It's systems that agents can operate with the same confidence and autonomy humans expect from well-designed APIs.
Want to see the full framework? Read the complete Agentic Data Stack Evaluation Framework for decision-makers and platform architects.
New to the concept? Start with What Is the Agentic Data Stack? for a high-level introduction.
Explore the tooling landscape: Browse our Resources hub covering catalog services, lake formats, SQL engines, semantic layers, ETL/ELT tools, BI tools, and data agents.
Source
This article is based on the Agentic Data Stack Evaluation Framework developed through research and discussion captured in this exported conversation, focusing on the shift from adoption primitives to mission outcomes in agent-ready systems.